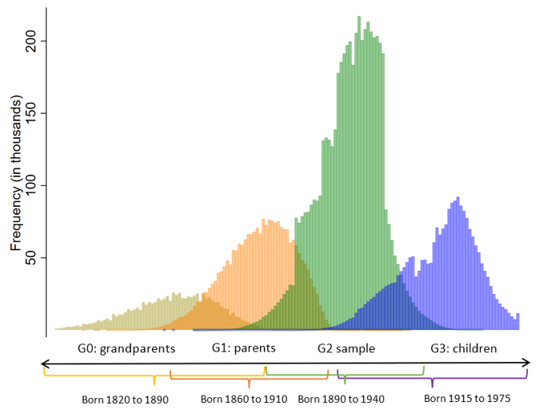
Intergenerational Structure
LIFE-M contains four generations of individuals. To create the data, LIFE-M samples from birth certificates. These cohorts are called generation 2 (G2) and were born from around 1890 to 1940. LIFE-M then links G2 to their parents (G1), grandparents (G0), and own children (G3). G2’s grandparents were born before 1890 (many of them contemporaries of the Union Army cohorts). G2 parents were born from around 1860 to 1910. G2’s children (G3) were born from 1915 forward.
Generational Structure and Cohort Distribution
Linking Sequence
LIFE-M’s linking process begins by reconstituting birth and marriage families of the late 19th and early 20th century birth cohorts (G2) (figure below, arrow 1). This requires linking birth records (G2) to one another using parents’ full names (G1) and other information such as parents’ birthplaces (when available). We also examine records with only one parent to identify cases of parent deaths and remarriage. The G2 birth certificates provide a link for at least two generations. Also, G2 can be linked to their own children (G3), because birth records contain mother’s birth names. This step allows the reconstruction of two to three generations of interrelated families. In addition, the resulting family sizes are compared to census tabulations to examine data quality.
Linking Sequence

Our second step (arrow 2) is to link marriage records by bride and groom name for G1 and G2, exact date of birth (allowing for over-reporting of age, Blank et al. (2009)), and place of birth (when available in the collection).
The third step is to link G2 to their grandparents (G0) using the 1920, 1910, 1900, and 1880 Censuses (arrow 3). Parents’ (birth or married) names (G1) are linked to the names in the 1920, 1910, and 1900 censuses. These censuses provide key information on birthplace, age, and race for G1, which allows us to link them backwards to the 1880 census. This step connects G2 to G0 and is important because it allows for the addition of G1’s early life family conditions, including G0 ancestry/heritage, economic circumstances such as occupation, race, and address.
The fourth step links four generations (G0, G1, G2, G3) to the full-count 1940 Census (arrow 4). This step uses full names (including birth and maiden names of women), exact birth dates/age, and birthplace. The 1940 Census is the first census to include rich information on educational attainment, wages and salary, and many employment outcomes. This linking is only possible for some of G0 (many will have passed away before 1940), but most of G1, G2 as adults (in their marriage families), and G3 as children (in birth families).
The final step (arrow 5) is to link G0-G3 to death records. The linking variables are full birth and/or married names, exact day of birth, place of birth (county/town), and parents’ names and place of birth when available in the collection. Almost all G0-G2 will have died in the time span covered by the death records, as will many of G3. Because death records span almost the entirety of the 20th century for most collections, we will observe longevity for at least three generations. We also link infant deaths to parents’ names to fill in missing birth records, because many infant deaths were not recorded as births (and this helps us reconstitute families further).
Supplemental funding allowed us to add cause of death for Ohio. See the LIFE-M Ohio Causes of Death Project for more information about these data.
